
Image super-resolution (SR) generally enhance the resolution of images. One of SR{\textquoteright}s main challenge is discovering mappings between low-resolution (LR) and high-resolution (HR) image patches. The invention learns patch upscaling projection matrices from a training set of images. Input images are divided into overlapping patches, which are normalized and transformed to a defined orientation. Different transformations can be recognized and dealt with by using a simple 2D-projection. The transformed patches are clustered, and cluster specific upscaling projection matrices and corresponding cluster centroids determined during training are applied to obtain upscaled patches. The upscaled patches are assembled to an upscaled image.
\
https://worldwide.espacenet.com/publicationDetails/biblio?II=2\&ND=3\&adjacent=true\&locale=en_EP\&FT=D\&date=20170511\&CC=US\&NR=2017132759A1\&KC=A1
}, issn = {US 20170132759 A1}, url = {https://register.epo.org/ipfwretrieve?apn=US.201615341080.A\&lng=en}, author = {E. Perez-Pellitero and Salvador, J. and Ruiz-Hidalgo, J. and Rosenhahn, B.} } @phdthesis {dPerez-Pellitero17, title = {Manifold Learning for Super Resolution}, year = {2017}, school = {Leibniz Universit{\"a}t Hannover}, address = {Hannover}, abstract = {The development pace of high-resolution displays has been so fast in the recent years that many images acquired with low-end capture devices are already outdated or will be shortly in time. Super Resolution is central to match the resolution of the already existing image content to that of current and future high resolution displays and applications. This dissertation is focused on learning how to upscale images from the statistics of natural images. We build on a sparsity model that uses learned coupled low- and high-resolution dictionaries in order to upscale images.
Firstly, we study how to adaptively build coupled dictionaries so that their content is semantically related with the input image. We do so by using a Bayesian selection stage which finds the best-fitted texture regions from the training dataset for each input image. The resulting adapted subset of patches is compressed into a coupled dictionary via sparse coding techniques.
We then shift from l1 to a more efficient l2 regularization, as introduced by Timofte et al. Instead of using their patch-to-dictionary decomposition, we propose a fully collaborative neighbor embedding approach. In this novel scheme, for each atom in the dictionary we create a densely populated neighborhood from an extensive training set of raw patches (i.e. in the order of hundreds of thousands). This generates more accurate regression functions.
We additionally propose using sublinear search structures such as spherical hashing and trees to speed up the nearest neighbor search involved in regression-based Super Resolution. We study the positive impact of antipodally invariant metrics for linear regression frameworks, and we propose two efficient solutions: (a) the Half Hypersphere Confinement, which enables antipodal invariance within the Euclidean space, and (b) the bimodal tree, whose split functions are designed to be antipodally invariant and which we use in the context of a Bayesian Super Resolution forest.
In our last contribution, we extend antipodal invariance by also taking into consideration the dihedral group of transforms (i.e. rotations and reflections). We study them as a group of symmetries within the high-dimensional manifold. We obtain the respective set of mirror-symmetry axes by means of a frequency analysis, and we use them to collapse the redundant variability, resulting in a reduced manifold span which, in turn, greatly improves quality performance and reduces the dictionary sizes.
}, author = {E. Perez-Pellitero}, editor = {Rosenhahn, B. and Ruiz-Hidalgo, J.} } @article {aPerez-Pellitero16, title = {Antipodally Invariant Metrics For Fast Regression-Based Super-Resolution}, journal = {IEEE Transactions on Image Processing}, volume = {25}, year = {2016}, month = {06/2016}, pages = {2468}, chapter = {2456}, abstract = {
Dictionary-based Super-Resolution algorithms usually select dictionary atoms based on distance or similarity metrics. Although the optimal selection of nearest neighbors is of central importance for such methods, the impact of using proper metrics for Super-Resolution (SR) has been overlooked in literature, mainly due to the vast usage of Euclidean distance. In this paper we present a very fast regression-based algorithm which builds on densely populated anchored neighborhoods and sublinear search structures. We perform a study of the nature of the features commonly used for SR, observing that those features usually lie in the unitary hypersphere, where every point has a diametrically opposite one, i.e. its antipode, with same module and angle, but opposite direction. Even though we validate the benefits of using antipodally invariant metrics, most of the binary splits use Euclidean distance, which does not handle antipodes optimally. In order to benefit from both worlds, we propose a simple yet effective Antipodally Invariant Transform (AIT) that can be easily included in the Euclidean distance calculation. We modify the original Spherical Hashing algorithm with this metric in our Antipodally Invariant Spherical Hashing scheme, obtaining the same performance as a pure antipodally invariant metric. We round up our contributions with a novel feature transform that obtains a better coarse approximation of the input image thanks to Iterative Back Projection. The performance of our method, which we named Antipodally Invariant Super-Resolution (AIS), improves quality (PSNR) and it is faster than any other state-of-the-art method.
}, doi = {10.1109/TIP.2016.2549362}, url = {http://perezpellitero.github.io/project_websites/ais_sr.html}, author = {E. Perez-Pellitero and Salvador, J. and Ruiz-Hidalgo, J. and Rosenhahn, B.} } @conference {cPerez-Pellitero16, title = {Half Hypersphere Confinement for Piecewise Linear Regression}, booktitle = {IEEE Winter Conference on Applications of Computer Vision}, year = {2016}, month = {03/2016}, address = {Lake Placid, NY, USA}, abstract = {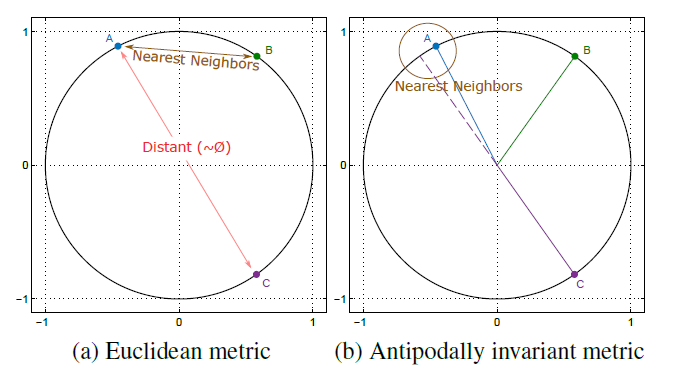 \ \ \
\ \ \
IIn this paper we study the characteristics of the metrics best suited for the piecewise regression algorithms, in which comparisons are usually made between normalized vectors that lie on the unitary hypersphere. Even though Euclidean distance has been widely used for this purpose, it is suboptimal since it does not handle antipodal points (i.e. diametrically opposite points) properly. Therefore, we propose the usage of antipodally invariant metrics and introduce the Half Hypersphere Confinement (HHC), a fast alternative to Multidimensional Scaling (MDS) that allows to map antipodally invariant distances in the Euclidean space with very little approximation error. The performance of our method, which we named HHC Regression (HHCR), applied to Super-Resolution (SR) improves both in quality (PSNR) and it is faster than any other state-of-the-art method. Additionally, under an application-agnostic interpretation of our regression framework, we also test our algorithm for denoising and depth upscaling with promising results.
}, doi = {10.1109/WACV.2016.7477651}, author = {E. Perez-Pellitero and Salvador, J. and Ruiz-Hidalgo, J. and Rosenhahn, B.} } @conference {cPerez-Pellitero, title = {PSyCo: Manifold Span Reduction for Super Resolution}, booktitle = {IEEE Conference on Computer Vision and Pattern Recognition}, year = {2016}, month = {06/2016}, address = {Las Vegas, Nevada, USA}, abstract = {\
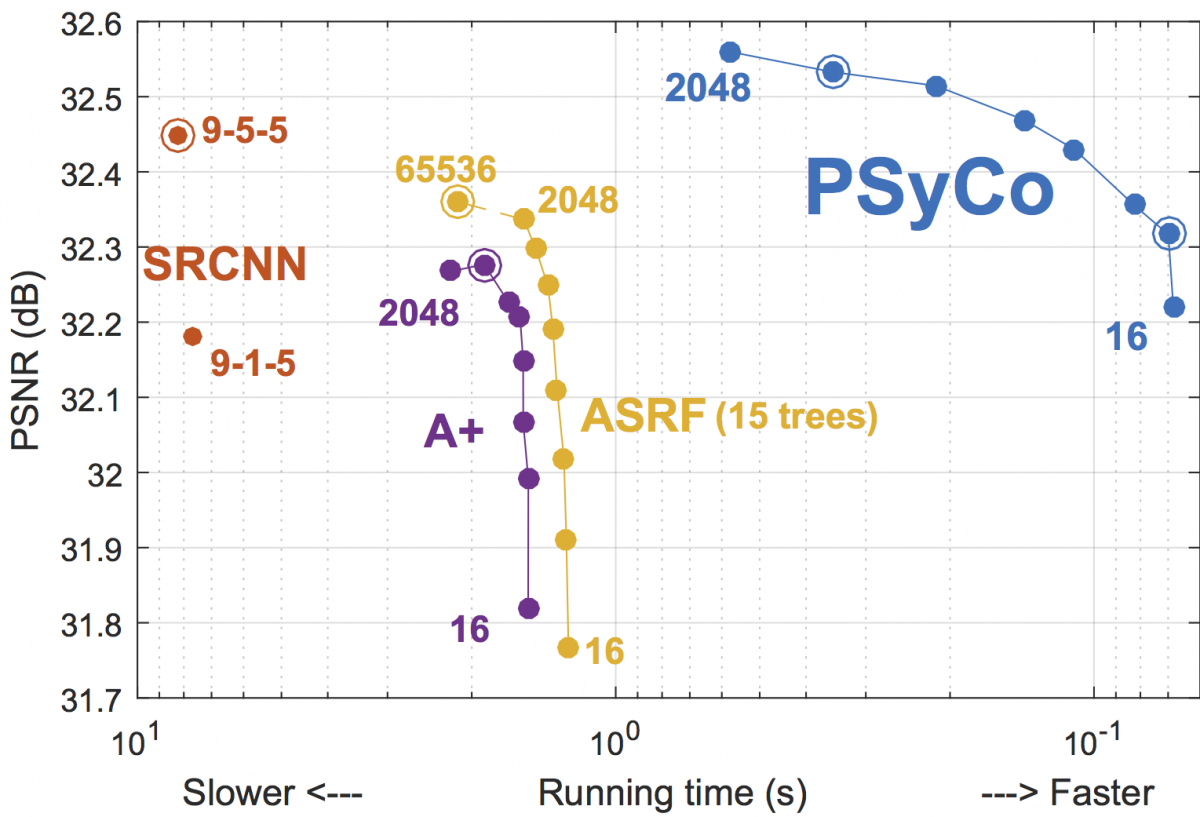
The main challenge in Super Resolution (SR) is to discover the mapping between the low- and high-resolution manifolds of image patches, a complex ill-posed problem which has recently been addressed through piecewise linear regression with promising results. In this paper we present a novel regression-based SR algorithm that benefits from an extended knowledge of the structure of both manifolds. We propose a transform that collapses the 16 variations induced from the dihedral group of transforms (i.e. rotations, vertical and horizontal reflections) and antipodality (i.e. di- ametrically opposed points in the unitary sphere) into a single primitive. The key idea of our transform is to study the different dihedral elements as a group of symmetries within the high-dimensional manifold. We obtain the respective set of mirror-symmetry axes by means of a frequency analysis of the dihedral elements, and we use them to collapse the redundant variability through a modified symmetry distance. The experimental validation of our algorithm shows the effectiveness of our approach, which obtains competitive quality with a dictionary of as little as 32 atoms (reducing other methods{\textquoteright} dictionaries by at least a factor of 32) and further pushing the state-of-the-art with a 1024 atoms dictionary.
}, url = {http://perezpellitero.github.io/}, author = {E. Perez-Pellitero and Salvador, J. and Ruiz-Hidalgo, J. and Rosenhahn, B.} } @conference {cPerez-Pellitero15, title = {Accelerating Super-Resolution for 4K Upscaling}, booktitle = {IEEE International Conference on Consumer Electronics}, year = {2015}, month = {01/2015}, address = {Las Vegas, NV, USA}, abstract = {This paper presents a fast Super-Resolution (SR) algorithm based on a selective patch processing. Motivated by the observation that some regions of images are smooth and unfocused and can be properly upscaled with fast interpolation methods, we locally estimate the probability of performing a degradation-free upscaling. Our proposed framework explores the usage of supervised machine learning techniques and tackles the problem using binary boosted tree classifiers. The applied upscaler is chosen based on the obtained probabilities: (1) A fast upscaler (e.g. bicubic interpolation) for those regions which are smooth or (2) a linear regression SR algorithm for those which are ill-posed. The proposed strategy accelerates SR by only processing the regions which benefit from it, thus not compromising quality. Furthermore all the algorithms composing the pipeline are naturally parallelizable and further speed-ups could be obtained.
}, doi = {10.1109/ICCE.2015.7066429}, author = {E. Perez-Pellitero and Salvador, J. and Ruiz-Hidalgo, J. and Rosenhahn, B.} } @conference {cPerez-Pellitero14, title = {Fast Super-Resolution via Dense Local Training and Inverse Regressor Search}, booktitle = {Asian Conference in Computer Vision (ACCV)}, year = {2014}, month = {11/2014}, address = {Singapore}, abstract = {Regression-based Super-Resolution (SR) addresses the up- scaling problem by learning a mapping function (i.e. regressor) from the low-resolution to the high-resolution manifold. Under the locally linear assumption, this complex non-linear mapping can be properly modeled by a set of linear regressors distributed across the manifold. In such methods, most of the testing time is spent searching for the right regressor within this trained set. In this paper we propose a novel inverse-search approach for regression-based SR. Instead of performing a search from the image to the dictionary of regressors, the search is done inversely from the regressors{\textquoteright} dictionary to the image patches. We approximate this framework by applying spherical hashing to both image and regressors, which reduces the inverse search into computing a trained function. Additionally, we propose an improved training scheme for SR linear regressors which improves perceived and objective quality. By merging both contributions we improve speed and quality compared to the state-of-the-art.
}, author = {E. Perez-Pellitero and Salvador, J. and Torres-Xirau, I. and Ruiz-Hidalgo, J. and Rosenhahn, B.} } @conference {cPerez-Pellitero13, title = {Bayesian region selection for adaptive dictionary-based Super-Resolution}, booktitle = {British Machine Vision Conference}, year = {2013}, month = {09/2013}, abstract = {\
The performance of dictionary-based super-resolution (SR) strongly depends on the contents of the training dataset. Nevertheless, many dictionary-based SR methods randomly select patches from of a larger set of training images to build their dictionaries,\ thus relying on patches being diverse enough. This paper describes an external-dictionary SR algorithm based on adaptively selecting an optimal subset of patches out of the training images. Each training image is divided into sub-image entities, named regions, of such size that texture consistency is preserved. For each input patch to super-resolve, the best-fitting region (with enough high-frequency energy) is found through a Bayesian selection. In order to handle the high number of regions in the train- ing dataset, a local Naive Bayes Nearest Neighbor (NBNN) approach is used. Trained with this adapted subset of patches, sparse coding SR is applied to recover the high-resolution image. Experimental results demonstrate that using our adaptive algorithm produces an improvement in SR performance with respect to non-adaptive training.\